💎 Git’s Data Model: The Elegance of Simplicity #
Git’s Building Blocks: The Immutable Objects #
Once a directory becomes a Git repository (identifiable by the hidden .git folder at its root), Git diligently monitors all files and subdirectories within it.
When you commit your work, you instruct Git to create a snapshot: an exact, complete representation of your entire project—every file and directory—at that precise moment. Critically, each snapshot Git records is immutable. Once written, it’s set in stone, forming a trustworthy and unalterable record of your project’s history.

As you develop your project, making changes and committing them, Git assembles a history as a sequence of these immutable snapshots. Each commit builds upon the last, creating a clear timeline of your project’s evolution.
If you were to visualize this journey, each snapshot (which is fundamentally a ‘commit’ object) would be a distinct marker on this timeline:
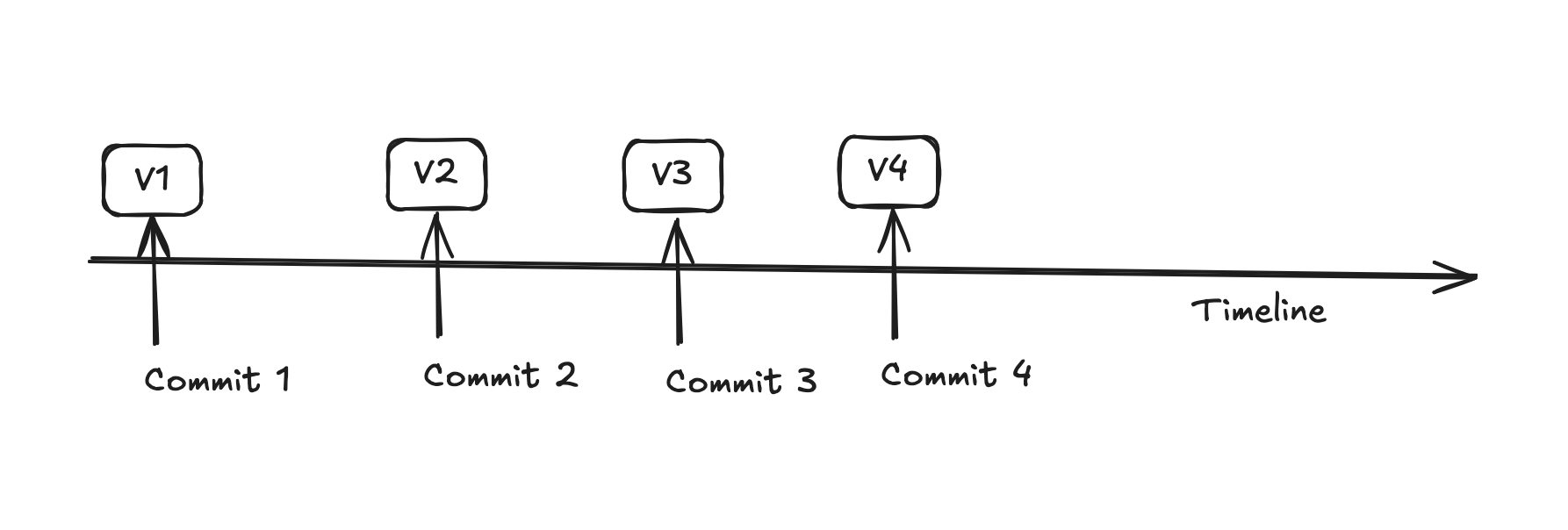
In the figure above, each snapshot (e.g., v3) represents the state of the repository at that precise moment. So, if one were to check out snapshot v3, the state of the files and directories would exactly match their state when the snapshot was created.
In Git terminology, these snapshots are called commits. A commit is an immutable object in Git. Once a commit is made, it is set in stone.
Each commit contains the complete set of files and directories representing a specific state of the project. For instance, if commit v3 had the following structure:
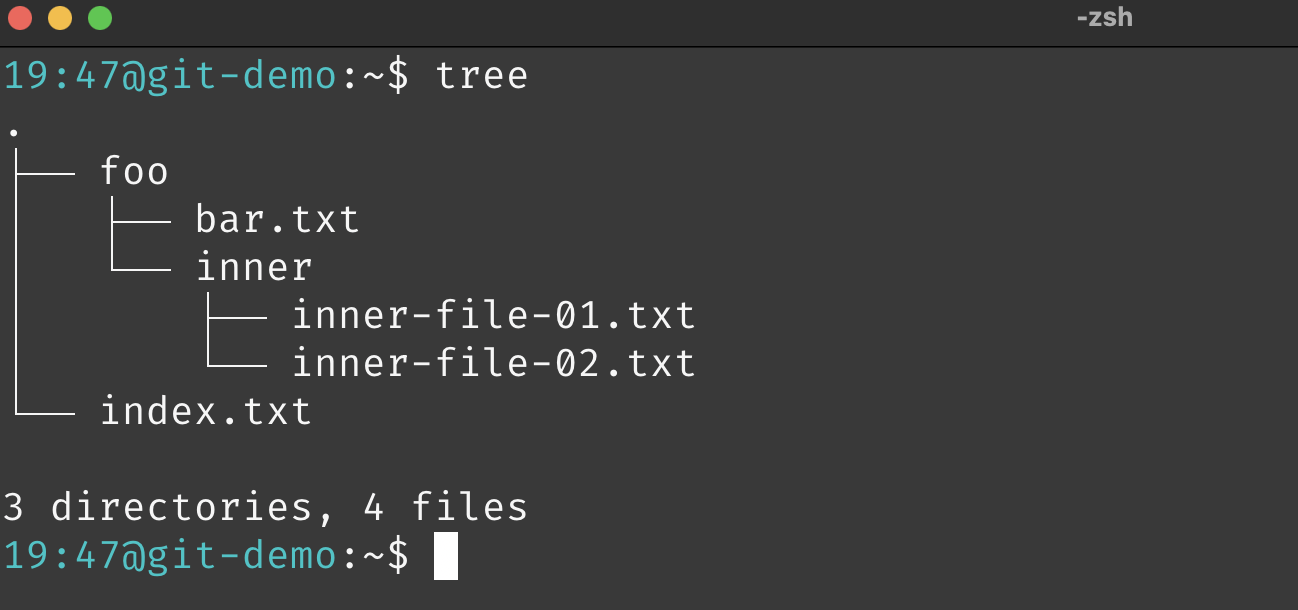
It contained 3 directories and 4 files. In Git’s data model, directories are represented as trees, and file contents are represented as blobs.
A root tree represents the top-level directory of the Git repository. In our example, the root tree corresponds to the git-demo directory. Each tree object represents a directory and can contain entries pointing to other trees (representing subdirectories) or blobs (representing file contents). Crucially, the filename is stored in the tree entry, not in the blob. A blob, therefore, purely represents the contents of a file. Just like commits, trees and blobs are also immutable objects, guaranteeing data integrity in Git. Files are retrieved exactly as they were stored.
SHA-1 Hash Function: #
A crucial and universal aspect of how Git handles these objects is that every object in Git is uniquely identified and its integrity verified by an SHA-1 hash. Understanding this concept is fundamental to grasping how Git works internally. Therefore, it’s important to understand the SHA-1 function before delving into the details of each of the above objects.
What is a hash function #
A hash function takes an input and converts it into a fixed-size string. The hash function consistently produces identical hashes for identical inputs. If h(x) represents a hash function, then
x1 = x2 => h(x1) = h(x2)
Hash functions are also designed for strong collision resistance, meaning it should be computationally infeasible to find different inputs producing the same output.
SHA-1 (Secure Hash Algorithm 1) is a cryptographic hash function that produces a 160-bit (40-character hexadecimal) hash value from any input message.
You’ve likely noticed the fixed-length (40-character hexadecimal) IDs associated with commits. These IDs are generated by the SHA-1 hash function and serve as unique identifiers for the commits. This process ensures that commits are deterministic (the same content always produces the same SHA-1 hash) and content-addressable (the ID is derived directly from the content).
Like commits, Git also creates SHA-1 keys for trees and blobs.
Git Immutable Objects Deep Dive: #
As mentioned above, Git has three fundamental immutable objects:
- Commits
- Trees
- Blobs
Let’s delve into each one of these.
Commit: #
As mentioned, a commit is a snapshot of the repository’s state at a given point in time. The simplest way to conceptualize project history might be as a linear sequence of commits. However, Git stores commits using a more flexible structure to support parallel streams of development, known as branching. Recall that a core requirement for Git was the ability to easily create branches for parallel work or experimentation and to seamlessly merge these branches back into the mainline.
Therefore, Git uses a more sophisticated data structure for commits: a directed acyclic graph (DAG).
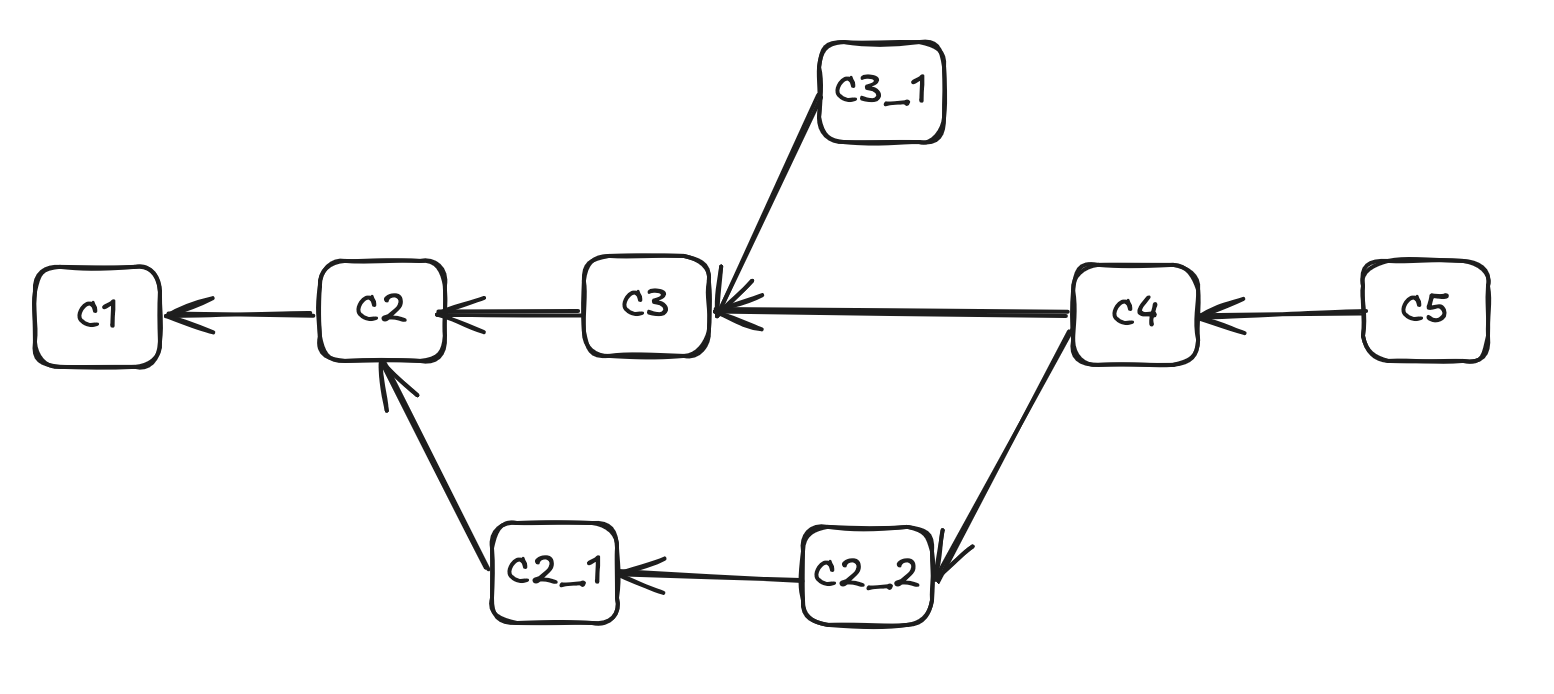
As shown in the diagram, a commit typically points to one or more parent commits (the initial commit has no parents, and merge commits have multiple parents). This model supports branching, allowing development to diverge from a strictly sequential timeline. When two distinct commits share the same parent, it signifies a point where development paths diverge. Conversely, a commit with two parent commits is known as a merge commit; it integrates changes from different branches.
Merge commits combine work from multiple lines of development, and there’s always a possibility of conflicting changes. Git can automatically merge branches if there are no conflicting changes. However, if conflicts arise (for example, changes in different branches modify the same lines in a file), Git will prompt for a manual merge. This requires a human committer to carefully review the changes from the involved branches and resolve the conflicts by selecting the appropriate changes.
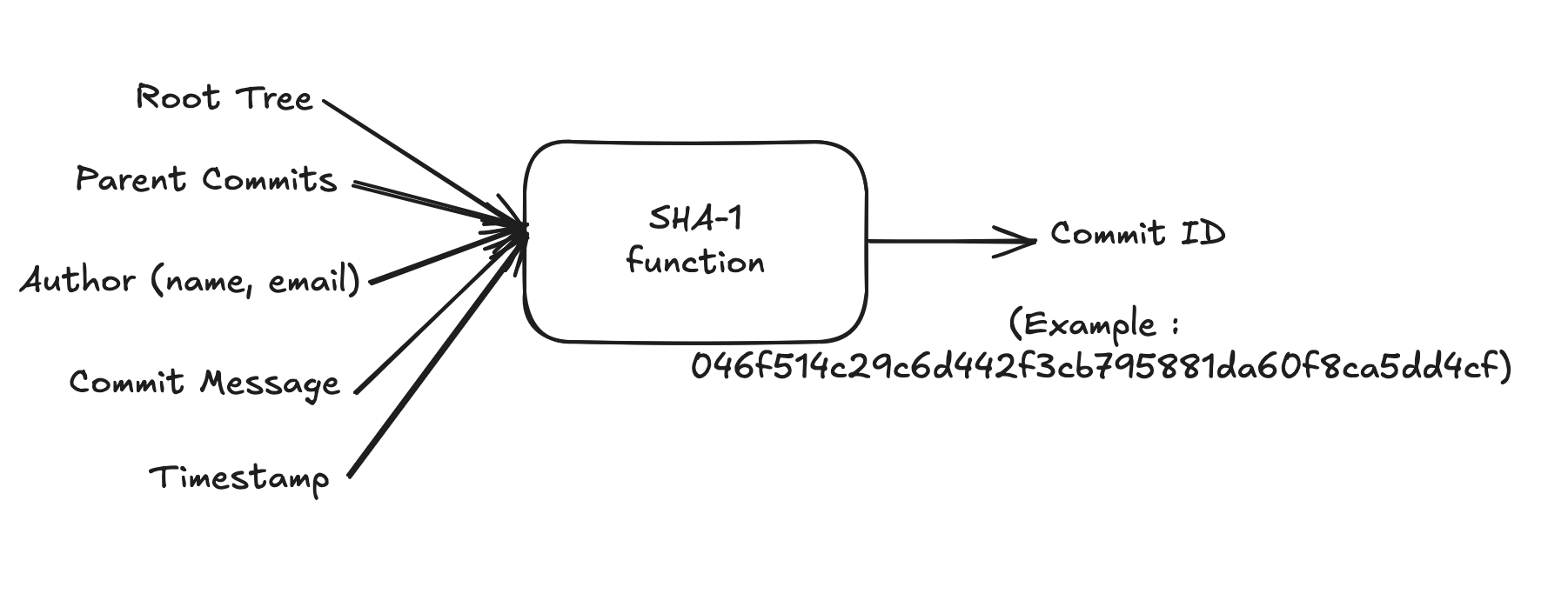
Git Commit Object Data Structure #
The structure of a commit object would look somewhat like the following. Please note that this is pseudocode, meant for illustration and not for exact accuracy.
type Commit struct {
Tree string // SHA1 hash of the root tree object
Parents []string // SHA1 hashes of parent commits
Committer ActorInfo // The author of the commit
Message string // The commit message (including timestamp)
}
The SHA-1 hash of the commit object is derived from all its attributes.
Tree: #
A tree object represents a directory. It contains entries for subdirectories (other trees) and files (blobs). Each entry includes the filename or directory name, its mode (e.g., executable status), its type (tree or blob), and a reference (SHA-1 hash) to the corresponding tree or blob object.
The structure of the Tree object would look somewhat like the following. Please note that this is for illustration and not an exact representation of Git’s internal storage.
// TreeEntry represents a single entry (file or subdirectory) within a Git tree.
type TreeEntry struct {
Mode string // File mode
Type string // Object type: "blob" (file) or "tree" (subdirectory)
SHA1 string // SHA1 hash of the blob or tree object this entry points to
Filename string // Name of the file or subdirectory
}
// Tree represents a Git tree object, which is essentially a directory listing.
// The tree's own SHA1 ID is derived from its content (the list of entries)
// and not stored as a field here.
type Tree struct {
Entries []TreeEntry // A sorted list of entries within this tree (directory)
}
Blob: #
At the most fundamental level of file storage in Git is the blob (Binary Large Object). A blob represents the exact contents of a file and nothing more. It’s a simple container for your data, devoid of any metadata like the filename, timestamp, or permissions. These details, as we’ve seen, are stored in tree objects.
When you add a file to Git and commit it, Git takes the content of that file, compresses it, and stores it as a blob object in its internal database (the .git/objects di
rectory). The “name” of this blob object, which is how Git refers to it internally, is its SHA-1 hash. This hash is calculated based purely on the content the blob holds, plus a small header indicating its type and size.
The structure of a blob may be represented somewhat like the following:
// Blob represents a Git blob object, which stores the raw content of a file.
// The blob's own SHA1 ID is derived from its content (plus a header)
// and not stored as a field here.
type Blob struct {
Content []byte // The raw byte content of the file
Size int // The size of the content in bytes (often part of the header for hashing)
}
Peek Into Git Objects #
Here is a Git subcommand that, while perhaps less common in daily workflows, effectively demonstrates how to list all objects in a Git repository:
git cat-file --batch-check --batch-all-objects
The above command lists objects in the repository in the format:
<sha1> <type> <size>
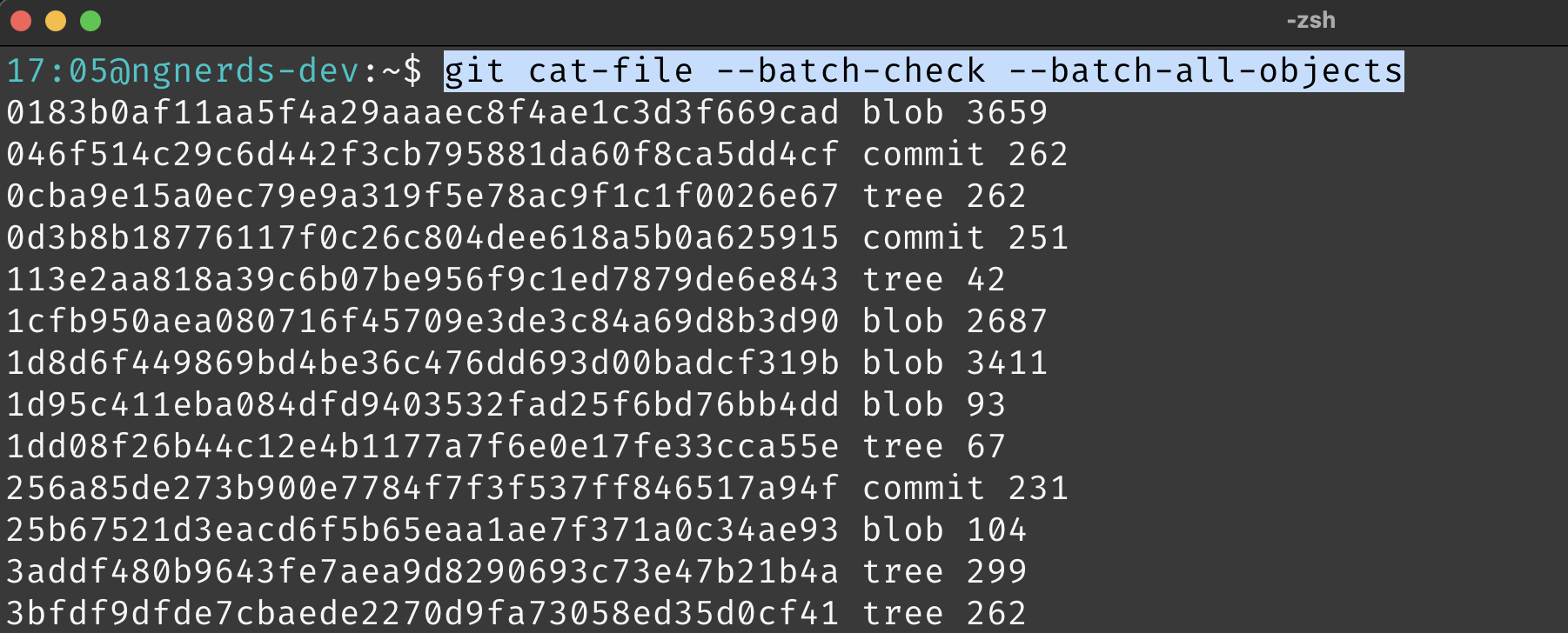
If I execute the cat-file subcommand with the SHA-1 of one of the trees listed above:
git cat-file -p <SHA1-of-a-tree-object>
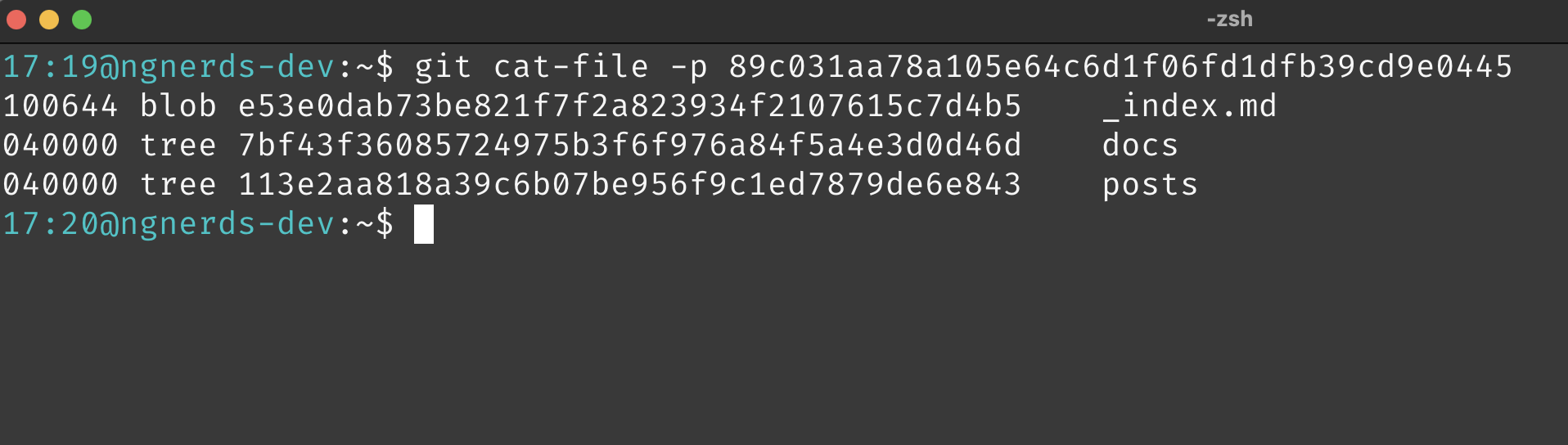
In the output above, you can see that the tree represents a directory that contains sub directories docs and posts and a file _index.md.
For a deeper exploration of Git’s internal data structures using commands, refer to the “Plumbing Commands” section in the official Git documentation.
In summary, this module has shown that Git stores repository data using three fundamental, immutable object types: commits, trees, and blobs. This immutability is crucial for maintaining data integrity in Git.